How IPFS Works Under The Hood
April 25, 2019 • ☕️ 4 min read
Language: 简体中文
Next generation Web, Web3, should be more decentralized and censorship resistant, which requires a more decentralized way for data storage. That is why IPFS, InterPlanetary File System, and Filecoin got so much attention, and invested by well known venture capitals like Y Combinator, Naval Ravikant, Andreessen Horowitz, Union Square Ventures Sequoia and Winklevoss Capital. Now let’s figure out how IPFS works under the hood.
From Where To What
IPFS created by Protocol Labs as a brand new data storage protocol, is a lot different from the current way data retrieved with HTTP on Web.
The current solution is from domain name to IP address and then server. There are two Single Point Of Failure here, one is the DNS service, the other is the server itself. Once domain is blocked, server shut down because of censorship, the data is not longer available. Such Web can not be free, the practitioners like you and me know this too well.
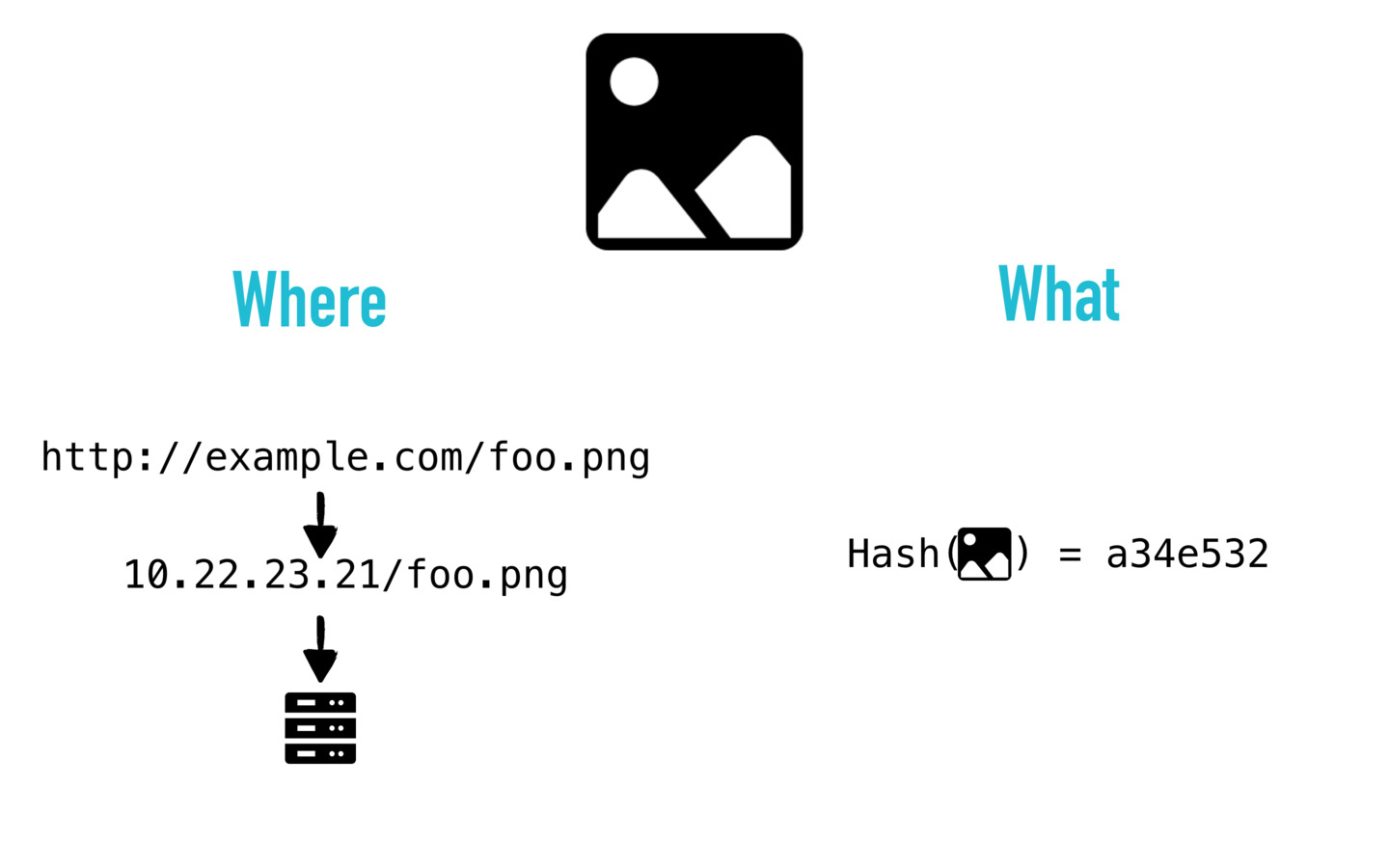
However, the solution IPFS gives is to retrieve by what it is rather than where it is. We get the file by its hash, because the IPFS always has the file named by its hash. A file hash maps to its content, that’s why we call the IPFS way is getting by what it is. This approach brings two advantages. NO.1, Once I get the file I can be sure it is not tempered, since the hash can be calculated and checked if it matches the filename. NO.2, Same content produce the same file name, we can safely delete files with same name and keep only one copy of the file to save space on Web.
To put it simply, IPFS retrieves data by hash, that means retrieving by the content of a file, by what it is.
From A Single Server To Decentralized Storage
IPFS also differs in the way how data is stored.
Storing content on a single server has obvious problems. Firstly, all users need to go for the same server and easily make the service slow. Secondly, this is vulnerable to DDOS attack, that is someone intentionally sends huge number of requests to make the service unavailable to others.
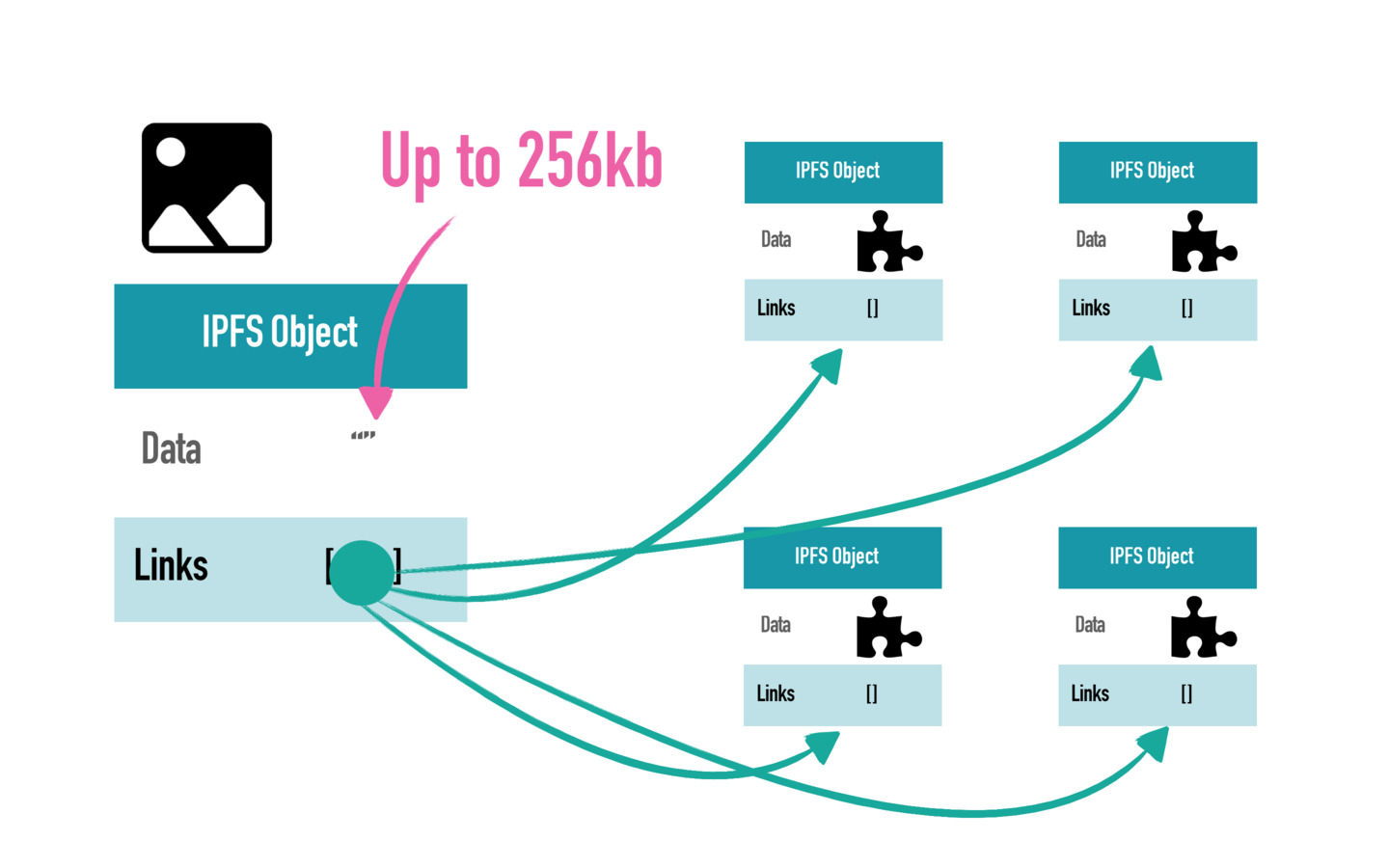
However, IPFS takes a distributed approach. Data is saved on all the clients using IPFS, forming a Your Client Is My Server architecture. When a file is saved, it is divided into smaller data blocks named IPFS Object, which can save up to 256k data in it. All the objects are organized into a Merkle Tree, and saved on different machines, therefore, IPFS is sometimes called The Merkle Web.
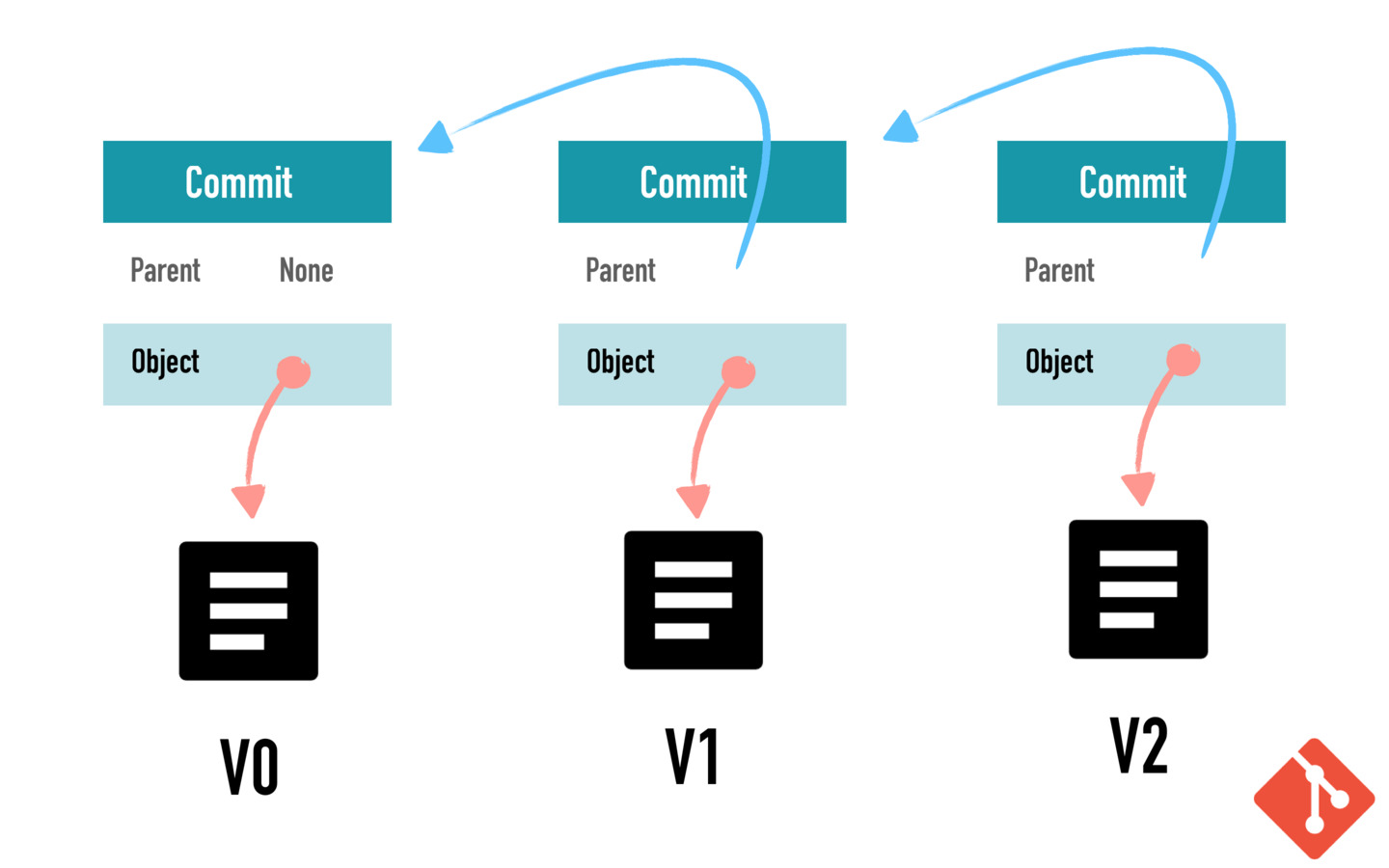
Furthermore, data is version controlled in IPFS. The way how data is saved is quite similar to Git. After all, Git by nature is a file system that locates data by content. IPFS data is immutable, this is exactly like Git as well. If a file is updated, then it is saved as a latest version, the older versions of this file kept untouched. Under the hood, all versions are saved like Git through commits, so that the same part of the file won’t be copied and cause storage waste.
That’s what I mean by IPFS takes a distributed way to save data.
Filecoin
IPFS alone leaves an important problem unsolved, that is how to motive people to save files for complete strangers. Inspired by blockchain projects like Bitcoin and Ethereum, Protocol Labs created Filecoin in order to provide an incentive layer for IPFS. Simply put it, you store files for others, you get Filecoins as a reward.
Storing data for others in IPFS is like mining for a blockchain. The creators of Filecoins knows that how big the blockchain mining pool can be, and wish to see people building server farms for IPFS, and use the power to store files for other people. Storing is like mining, which gets rewarded. On the other hand, I can spend Filecoins to motivate people to save files for me.
People holding Filecoins are share holders of IPFS network. They are more likely to be willing to maintain the whole system. If the ecosystem gets stronger, the price of Filecoin will rise.
At the same time, Filecoin is by design to encourage right user behavior. Say, encouraging people to save just enough copies of a file, so that when part of the servers are taken down, the data will still be available. That’s how Filecoin can help IPFS in the sense of fast adoption.
Conclusion
IPFS is aimed for serving as an alternative to HTTP based Web architecture. To conclude this episode, I want to stress on several points. Firstly, IPFS finds a file by what it is not where it is. Secondly, IPFS saves data in a distributed way, organizes objects into the Merkle Tree. Thirdly, Filecoin provides the incentive for IPFS’s mass adoption。
IPFS alone can not be the next web, it takes other components to really rebuild a next Web. I recommend blockstack if you want to check a possible full stack sultion for the next generation Web.
Ref: